TensorCore WMMA 编程
1 Tensor Core
矩阵乘法在进行行列相乘时需要逐元素的相乘累加。这个过程可以使用乘积累加指令FMA(Fused Multiply–accumulate operation)完成。

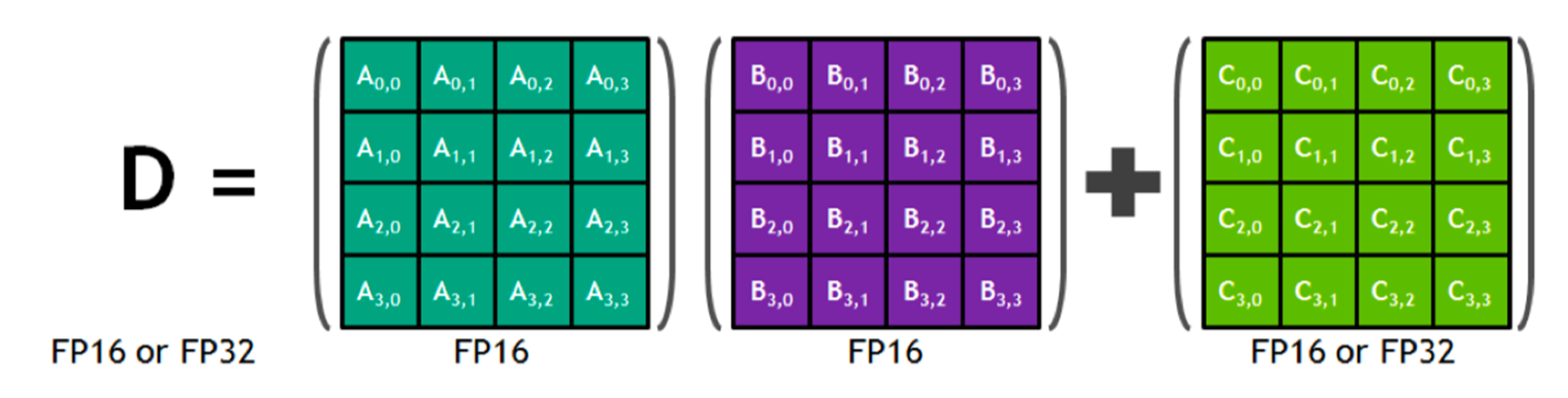
TensorCore是一种用于快速计算矩阵乘法的硬件(matrix multiply-and accumulation ,MAC)。
TensorCore可以原生计算$4 \times 4\times4$ 规模的矩阵乘法。CUDA 9.0以后支持$16 \times 16 \times 16$ 规模的矩阵乘法。
2 WMMA 编程
在利用cuda进行矩阵计算时需要对矩阵进行切片划分,要将矩阵切分至合适的大小。通常每个warp计算$16 \times 16 \times 16$规模的矩阵计算。
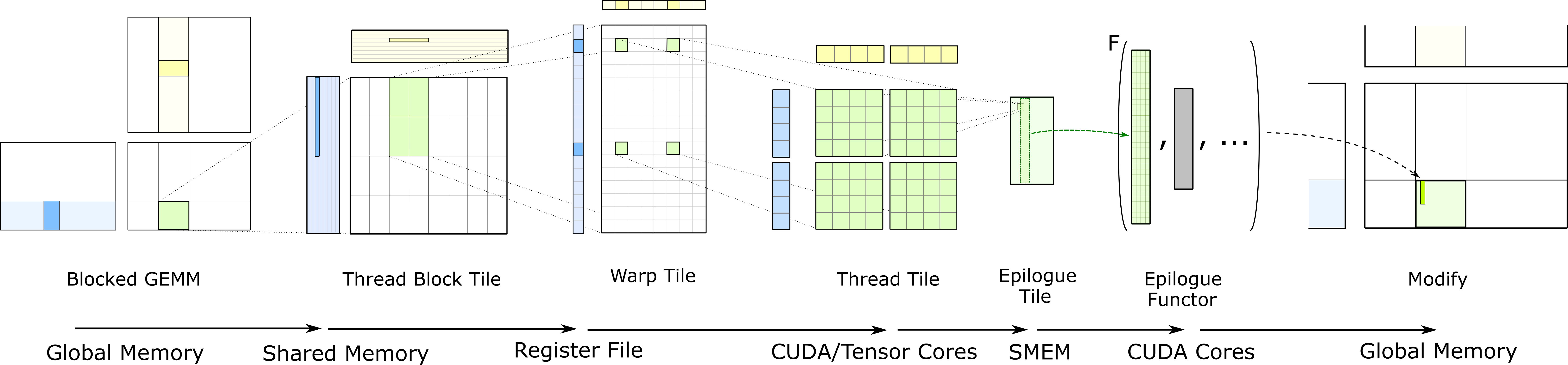
cuda提供了WMMA API用于调用TensorCore进行矩阵计算。
1 | template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment; |
fragment: 用于声明矩阵片段。
load_matrix_sync: 用于将数据加载到矩阵片段中。
store_matrix_sync: 用于将矩阵片段存储回存储空间。
fill_fragment: 填充矩阵片段。
mma_sync: 计算矩阵。
注意_sync表示的线程同步,所以相应的API接口必须同一线程束内的所有线程均可到达。
1 |
|
下面给出的是利用CudaCore进行计算的示例代码。
1 | __global__ void simtNaiveKernel(const uint8 *__restrict__ A, const uint8 *__restrict__ B, uint32_t *__restrict__ C, size_t M, |
CudaCore和TensorCore对比参考如下示意图。CudaCore以线程为单位,TensorCore以线程束为单位。
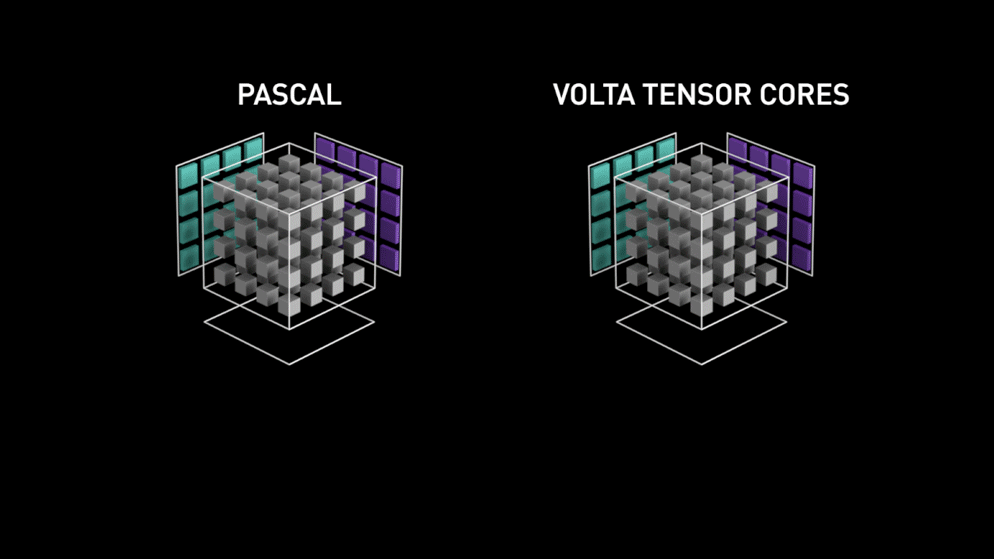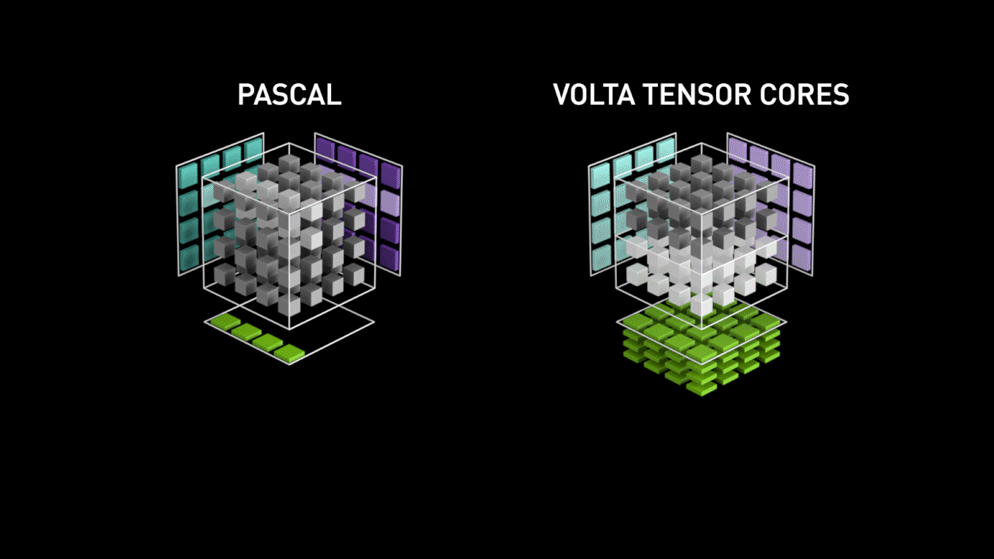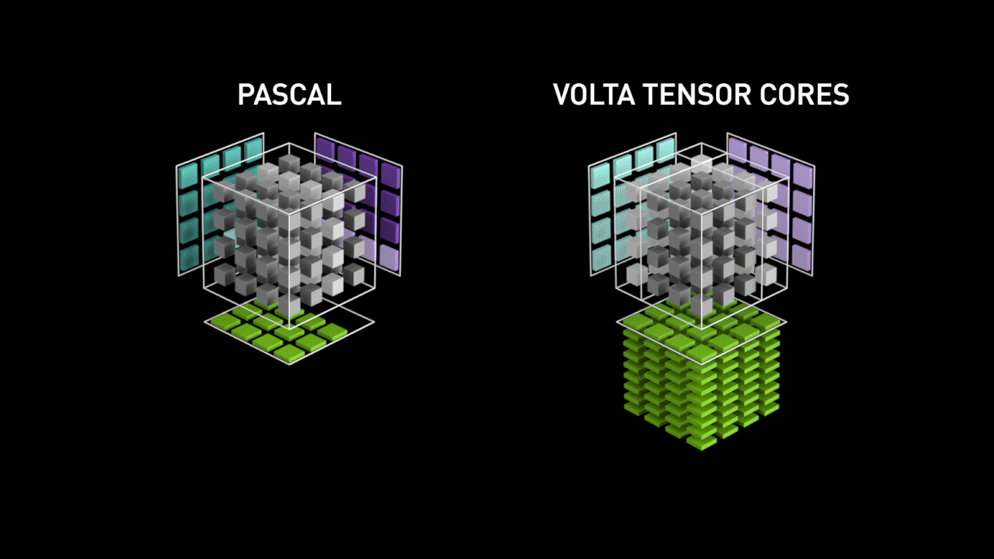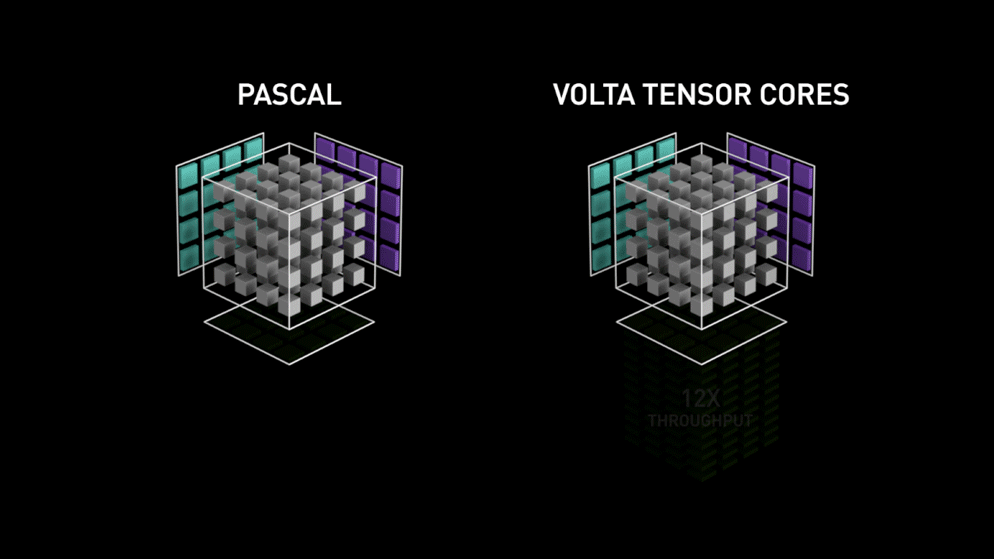
3 线程映射
$16 \times 16 \times 16$ 矩阵乘法中每一个线程对应8个uint8数据,数据和线程的映射关系如下图所示。
1 | template<> class fragment<matrix_a, 16, 16, 16, unsigned char, row_major> : public __frag_base<unsigned char, 8> {}; |

参考资料
[1]PTX ISA 8.5[EB/OL]. [2024-07-03]. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-multiply-accumulate-instructions.
[2]Programming Tensor Cores in CUDA 9 | NVIDIA Technical Blog[EB/OL]. [2024-07-03]. https://developer.nvidia.com/blog/programming-tensor-cores-cuda-9/.
[3]NVIDIA深度学习Tensor Core全面解析(上篇) | 雷峰网[EB/OL]. [2024-07-03]. https://www.leiphone.com/category/ai/RsZr7QRlQMfhMwOU.html.
[4]BRUCE-LEE-LY. Nvidia Tensor Core-Preliminary Exploration[EB/OL]//Medium. (2023-09-25)[2024-07-03]. https://bruce-lee-ly.medium.com/nvidia-tensor-core-preliminary-exploration-10618787615a.
[5]BRUCE-LEE-LY. Nvidia Tensor Core-Getting Started with WMMA API Programming[EB/OL]//Medium. (2023-09-25)[2024-07-03]. https://bruce-lee-ly.medium.com/nvidia-tensor-core-introduction-to-wmma-api-programming-21bcfee4ec45.
[6]BRUCE-LEE-LY. Nvidia Tensor Core-Getting Started with MMA PTX Programming[EB/OL]//Medium. (2023-09-25)[2024-07-03]. https://bruce-lee-ly.medium.com/nvidia-tensor-core-getting-started-with-mma-ptx-programming-508e44a6cb7d.
[7]BRUCE-LEE-LY. Nvidia Tensor Core-Getting Started with MMA PTX Programming[EB/OL]//Medium. (2023-09-25)[2024-07-03]. https://bruce-lee-ly.medium.com/nvidia-tensor-core-getting-started-with-mma-ptx-programming-508e44a6cb7d.
[8]YEH T T. Accelerator Architectures for Machine Learning[EB/OL].[2024-07-03].lecture-8.pdf (nycu.edu.tw)



